A System Dynamics Perspective on Structured Ignorance
Every knowledge system has a feedback structure. Information gets created, indexed, retrieved – and reinforced. The more a concept is cited, the more it crowds out adjacent, unnamed territory. This is not a failure of search.
It is a structural property of how knowledge accumulates: a reinforcing loop that amplifies the known while systematically depressing. The signal of the unknown.
Scio nescio. Sciamus nos nescire.
System Dynamics – the discipline developed at MIT by Jay Forrester – models how stocks and flows create the behavior of complex systems over time.
Applied to knowledge systems, the insight is precise:
The stock of “answered questions” grows through a flow of indexed content. But the stock of “unasked questions” has no inflow – because the system contains no feedback loop that makes absence visible.
The Ignorance Graph is a missing feedback structure. It maps the territory where reinforcing loops have not yet formed – where questions exist that no corpus has ever processed, where concepts carry real-world weight but carry zero search authority.
It does not compete with the Knowledge Graph. It operates where the Knowledge Graph’s own dynamics have produced a structural blind spot.
What a causal loop diagram of any knowledge domain reveals: consensus creates visibility, visibility attracts content, content reinforces consensus — while the balancing loop that should surface missing knowledge remains unbuilt.
The Ignorance Graph builds it.
What is the Ignorance Graph in detail?
The Ignorance Graph begins where the Scientific Consensus, the Knowledge Graph (Google), the SERP Consensus end. It is the turning point for scientific research and web search. Every search engine, every knowledge base, every AI model shares the same structural blind spot: they can only retrieve what already exists in their corpus. What has never been written, named, or indexed is invisible to them — and to the people using them.
The Scientific Consensus and the SERP Consensus are semantically related through their respective knowledge gaps. The Ignorance Graph operationalizes this connection by mapping missing entities and unanswered questions. It provides structured research environments for LLMs and Generative AI, enabling the systematic identification of latent research potentials.
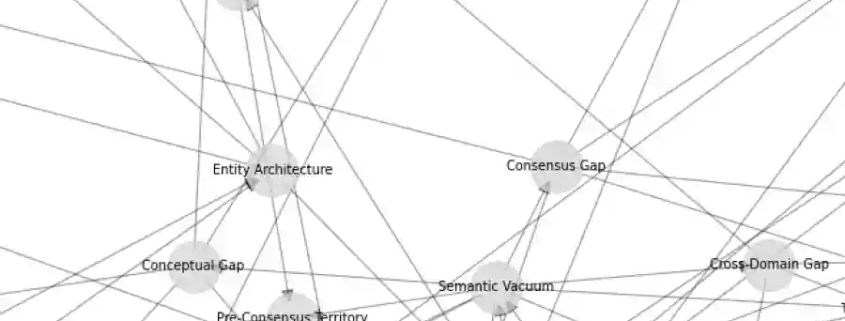
Part of an Ignorance Graph Map
The Ignorance Graph is the methodology for finding invisible knowledge territory.
It operates not by analyzing what is known, but by mapping what is systematically absent — the concepts for which no authoritative content exists anywhere in global search results.
How much consensus lives in the SERP for your topic? Check it here.
What the Ignorance Graph finds
For any topic or domain, there is a layer in search results where content converges around shared claims, shared framings, and shared knowledge limits. Below that layer, in the space where consensus has not yet formed, entire categories of meaningful questions go unanswered — not because the answers don’t exist, but because no one has yet positioned an answer as authoritative.
The Ignorance Graph identifies those gaps before they close
Why it matters: In a search landscape where most content strategies compete for the same established territory, the most durable positions are found in the spaces that haven’t yet been occupied. This is not speculation — it is a structural property of how knowledge systems work.
When a concept has no established answer in global search results, the first authoritative definition does not compete. It becomes the reference.
Where to begin
Read the definition: → What is the Ignorance Graph?
Understand the methodology: → How it works
See the core concept: → SERP Consensus